t-SNE
t-SNE (t-Distributed Stochastic Gradient Descent)是一種常用來視覺化資料分佈的工具。
簡介
相較於Principal Component Analysis (PCA)是用線性代數的方法(SVD)來將資料投射到代表性較高的空間上,t-SNE分別將每個點在空間中找到一個位置,而期待那個位置能和其他資料所對應到的位置有所區隔。
數學理論
Stochastic Neighbor Embedding
Model
Stochastic Neighbor Embedding (SNE) 是t-SNE的前身。其基本精神是:將兩個資料點的距離定義為選擇為鄰居的條件機率。舉 選擇 的情況,條件機率為 ,應該跟此兩點的距離相關(事實上非常直覺,機率正比於中心位於 的高斯分佈)。
同樣的例子精確的以數學式來表示 投影到二維平面時,會得到對應的點 和 ,同樣的概念利用 來表示,不過其標準差被設定為固定的值 ,這是一個normalization的概念。 注意到這個機率是非對稱的()。另外, 。
如何要決定 ?很明顯對於每個點 $i$ 都應該有不一樣的值。對於資料集中的區域,這個標準差應該很小(不可能有太多點在一個標準差內)。因此這個值應該跟資料分佈有關。
Perplexity
perplexity可能有好幾種相似的意義:它可能代表一個機率分佈容易被預測的程度;它可能代表一個model分散的程度;它也可能代表一個預測模型預測正確的程度。在SNE中perplexity是一個必須由使用者設定的值,被用來決定 是多少。perplexity被定義為
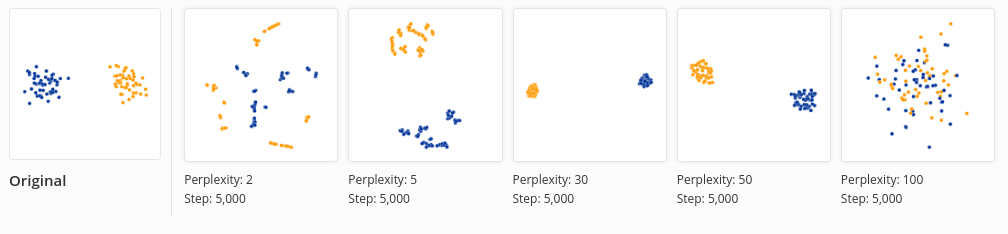
perplexity上升會使得 隨之上升(同調遞增),可以把perplexity大概解釋成有效的鄰近資料點。由上圖的變化大概可以猜測,perplexity變大的時候,有效的鄰近資料點也增加,因此分佈比較考慮全體的狀況。小的perplexity會讓每個點比較考慮local的情況,因此分佈是多個小的群集散落。
Training
SNE利用Stochastic Gradient Descent (SGD) 來減少兩者機率差距。其cost function是
將 對 做偏微分得到update的方程式 如果說perplexity決定了model怎麼看待這些資料之間的距離,每一次update就是像在兩兩個mapping後的資料點間建立一個吸引/排斥力,使得 能夠接近 ,其方向是 (paper上說,就像是彈簧一樣)。
t-SNE
t-SNE調整了SNE的cost function,使得兩兩間的cost是對稱的。在降維後的分佈 也不再使用高斯分佈,而是使用Student t分佈。主要是想解決兩個問題:
- cost function難以optimize。通常原本的SGD會再加上很大的momentum來避免被停在不好的local minimum裡。但這會使得選擇momentum變成一個問題。
- 在原本的SNE中,如果非常接近的幾個點能被正確mapping的話,那較遠一些的那些點就會變得離太遠。
重新被定義的變數如下
early exaggeration
在開始optimize cost function的時候,將 乘以某個值。其造成的結果是:一開始資料集中的cluster會分佈的更緊密,而不同cluster的距離會增加,因此更有機會找到適當的mapping。
random walk
一個加速方法,尋找原始資料中比較具代表性的點(例如距離過近的點就不會都被選中),然後才做t-SNE。
結論
缺點
以下三點來自原始論文
- 因為使用Student-t分佈,t-SNE可能不適合用在降維後維度超過3的應用。
- 對於資料特徵維度過大(此維度並非原始資料的維度,而是指underlying可能具有的維度)情況表現可能不好。原始paper建議可能可以先將原始資料先train一個deep autoencoder降維再來套用t-SNE。
- t-SNE的cost function不是一個convex(能夠穩定下降到local minimum)。因此需要一些training上的optimization來達到local minimum。
使用
scikit-learn有tsne的套件。
另外,這篇文章提供動畫以及說明來展示t-SNE的特性。