Principal Component Analysis (PCA)
主成份分析(PCA)是一個快速而且很有效的分析方式。當你要降維的時候、畫散佈圖觀察趨勢的時候第一個就是他了。
簡介

這邊引用一張來自Cross Validated的圖。
觀察圖中旋轉的直線,你可以發現當直線旋轉到某個角度的時候,藍點在直線上的投影的分佈最大(也就是說,variance最大)。現在假設我們想要了解x座標和y座標之間有什麼關係。那或許這個直線就是我們想要知道的關係,而所有點到這條直線的長度(圖上的紅線)是雜訊。使用PCA,我們期待可以找到一個座標轉換,使得轉換後的座標軸能最代表資料的分佈,而能明顯觀察出雜訊。
數學理論
座標轉換
假設我們用一個 維的向量 來代表我們的資料,則線性座標轉換可以用一個矩陣 來表示,使得 是轉換後的向量。PCA即是要找一個好的座標轉換。
所以這個問題現在變成:怎樣才算是一個好的座標轉換。也就是說, 的什麼分佈特性能夠比原來的資料還要好。
(Sample) Variance & Covariance
首先先定義(sample) variance和(sample) covariance。假設 是一個 的矩陣, 的每一行都是一筆 維的資料。則 是一個 的矩陣,被定義為 的sample variance matrix。 的第 個元素代表第 個維度和第 個維度的covariance。在 的對角線上, 是第 個維度的variance。
同樣從最上面的圖來看。我們很明顯要找的是藍點在直線上的投影的分佈最大的那個座標系。此結果在 中的對應就是variance能夠越大越好。利用這個方式,我們也可以比較哪一個維度的variance比較大,那些維度的資料就更能表示我們的資料;相反的,variance比較小的資料可以考慮丟棄(因為variance很小表示資料十分接近),對於我們分類或是預測的工作比較沒有效果。
再者要考慮的是redundancy的問題。這裡引用的圖是來自參考資料1的圖1。
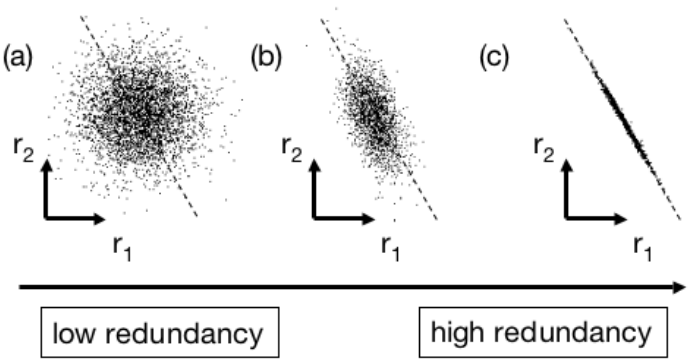
觀察圖(c),如果有兩個維度的資料是這樣的分佈,雖然我們不能丟棄任何一個維度的資料,但是很明顯這兩個維度之間有某個關聯,轉換座標後就能減少維度來表示。相反如圖(a),我們不能明顯看出這兩個維度的關聯,因此轉換座標就沒有作用。當然我們希望轉換完的座標能夠越接近圖(a)的情況。
此結果在 中的對應就是covariance。圖(a)中兩個維度的covariance接近 ,而圖(c)的covariance非常大。
綜合以上的討論,我們希望 的條件是這樣
Singular Value Decomposition (SVD)
假設 是一個 的矩陣,則SVD保證我們能找到一個拆解 的方式,使得 且 首先,我們先找出所有 和 的eigenvalue (他們的eigenvalue是一樣的)和對應的eigenvector 、 。因此,
則 我們可以簡單驗證如下 可得 的每一列就是 的eigenvector。對 的驗證也是一樣的。
Principal Component Analysis
解釋完SVD,接下來是將它套用PCA上。同樣假設 是一個 的矩陣, 的每一行都是一筆 維的資料,而 是我們要找的座標轉換。則
如果我們選擇 的eigenvector組合成的矩陣 為 ,則 則一切都變得很完美! 是一個對角線上有值,而非對角線上都是0的向量,代表 的每一個維度都盡可能達到variance最大,而兩個維度間的covariance都是0。
結論
特性、限制、以及可能的解答
PCA是線性的

一個簡單的範例:對於上圖(來自scikit-learn)的分佈,PCA沒辦法找到一個很好的方式,因為這牽涉到平移以及極座標的轉換。對此,有一個方式是將他投影到更高維度再降維,而這就是Kernel PCA的核心概念。
用variance和covariance來代表資料的分佈
這其實是一個很強的限制。如果我們只有得到variance和mean,則一個唯一確定的分佈是高斯分佈。所以對於不是高斯分佈的資料,PCA沒辦法給出很好的答案。如果我們不是兩個維度covariance為0的結果,而是兩個維度的分佈在機率上是獨立的,這就是Independent Component Analysis (ICA)的核心概念。
PCA得到唯一解
PCA不用下任何參數,過程也沒有任何使用到亂數的地方。這代表使用PCA會得到唯一解。沒有任何參數也代表了,沒有任何方法可以優化PCA的結果(除非已經知道資料的分佈而做適當的前處理;可是大部分的情況中,這就是我們使用PCA的原因...)。
使用PCA
在Python上,直接使用sciki-learn的PCA模組,完全沒必要自己寫...。
參考資料
1. A Tutorial on Principal Component Aanlysis (pdf) ↩
2. Singular Value Decomposition (SVD) tutorial ↩